以前、OpenFOAMのPimpleFoamの小規模並列計算のベンチマークを取りました。CPUはRyzen 1950Xです。結果、300万Cellを超えると並列効率が横ばいになりました。詳しくはこちら。
今回はメモリを追加し並列効率が改善するか調査しました。
変更点
PCケースを改造して、クーラー位置を見直しメモリを追加しました。詳しくはこちら。

これにより、メモリを16GB(8GB×2枚)⇒32GB(8GB×4枚)に増設しました。
ベンチマークモデル
セル数は294万Cellのみ検討。あとは前回と同様です。
- ソルバー:PimpleFoam
- 乱流モデル:LES Smagorinsky
- メッシャー:SnappyHexMesh
- セル数: 294万
- End time: 3秒
- 並列数:1,2,4,8
結果
計算時間を比較してみます。
| 並列数 | 計算時間(秒) | |
| RAM:16GB | RAM:32GB | |
| 1 | 24372 | 22357 |
| 2 | 15110 | 14031 |
| 4 | 11783 | 8426 |
| 8 | 11302 | 7634 |
グラフにすると以下の通り。
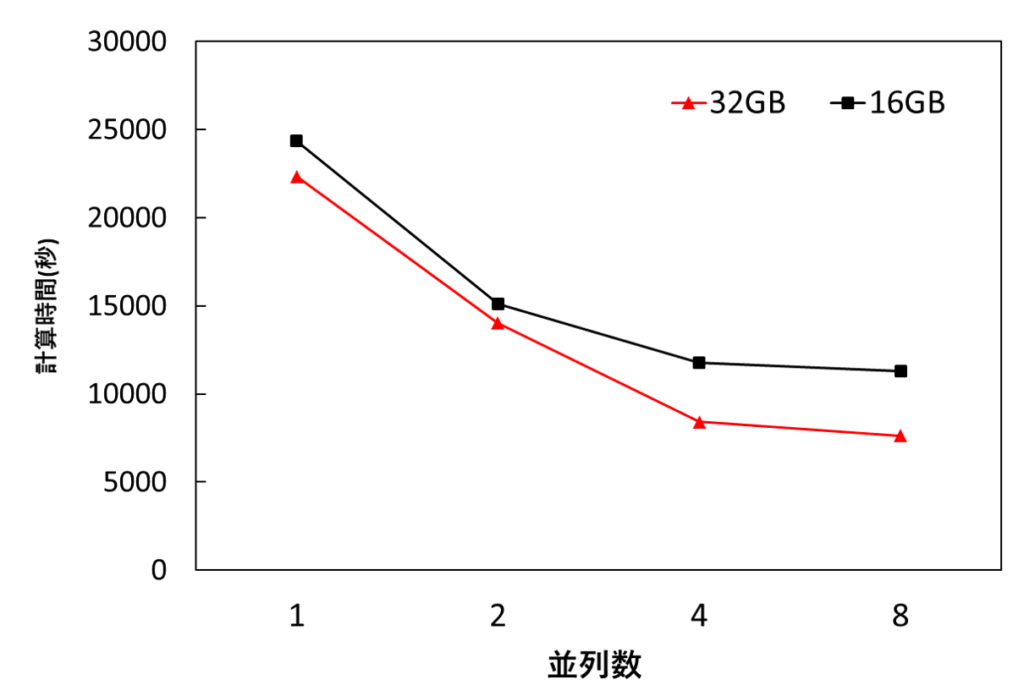 16GBの場合は2並列以降で計算時間の短縮が緩やかになっていますが、32GBとすると、4並列以降も計算時間が短縮されています。それでは並列効率を見ていきます。
16GBの場合は2並列以降で計算時間の短縮が緩やかになっていますが、32GBとすると、4並列以降も計算時間が短縮されています。それでは並列効率を見ていきます。
並列効率=nCPUでの計算時間/1CPUでの計算時間
メモリ追加前後で比較します。左側がRAM16GB、右側が32GBの結果。
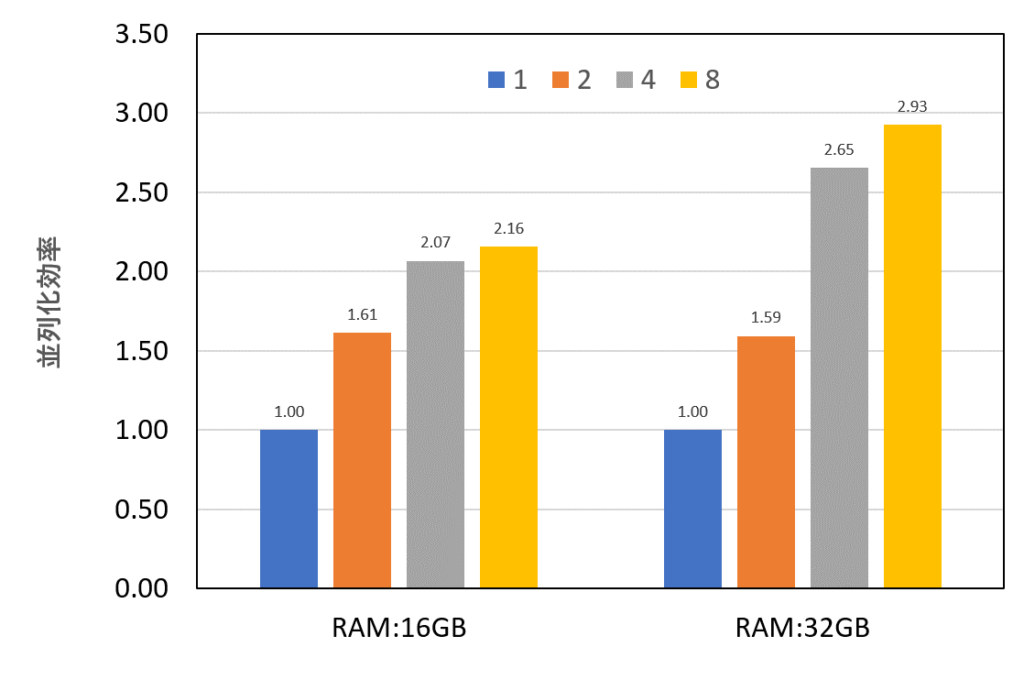
メモリ追加によって4並列以降の並列効率が改善しています。メモリを追加してよかった!
CPUの構成とメモリモード
Ryzen1950Xではその構成上、2つのメモリモードを使用することができます。メモリモードを知らなかったのでまずそこから勉強を兼ねて調べてみました。
※AMDのプレゼン資料がめちゃ参考になりました。あと、以下のサイト。

AMDのプレゼン資料を参照するとRyzen1950Xの中身は8コアが1まとまり(2チャンネル)になっており、それが2つ計4チャンネルで16コアの構成で、これをMulti Chip Module:MCMというらしい。
各チャンネルには4つのメモリ(4DMMS)が割り当てられており、4チャンネルで合計8枚のメモリを認識できます。

UMAモードは、4チャンネルのメモリコントローラを並列動作させることで広いメモリ帯域幅を実現するが、メモリアクセスのコストが大きく、レイテンシが大きくなるようです。
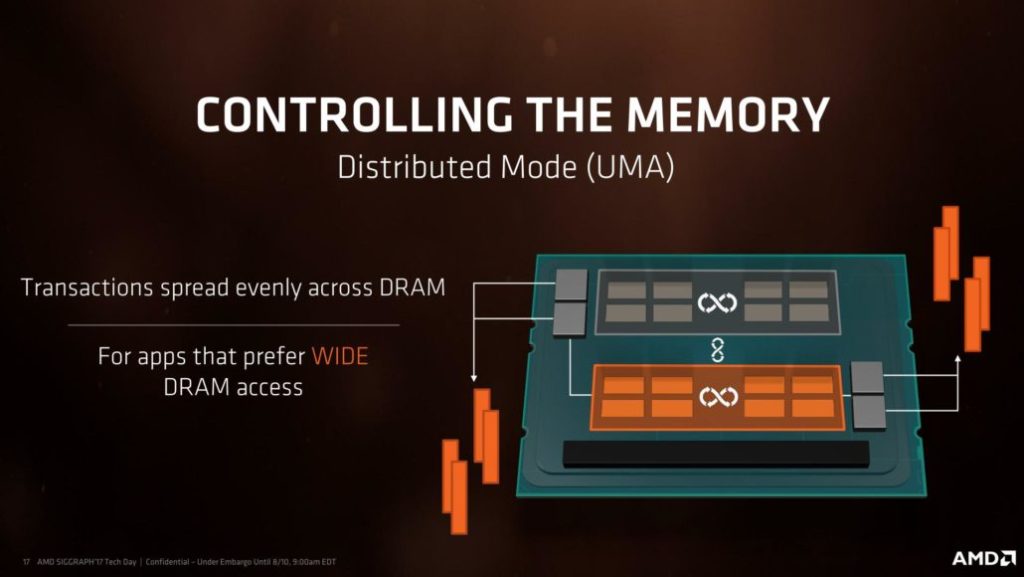
一方のNUMAモードは、アプリケーションをCPUに近いメモリへ割り当てるため、UMAと比べるとレイテンシの減少が望めます。しかし、4チャンネルの分散アクセスをしなくなるため、メモリ帯域幅はUMAに比べて小さくなってしまいます。

ここまで調べた限りでは、UMAよりNUMAの方がいいんでは?と感じます。調べてみるとUMAよりNUMAを推しているソースが多かったです。
さて、今回のベンチマークはどっちのメモリモードで行ったのか?
BIOSでメモリモードを調べたところ、デフォルト設定の”AUTO”になっていました。
Ryzen masterを確認したところ、AUTOとすると分散(UMA)になっていました。これは予想外。試しにローカル(NUMA)に変更して、8並列の計算を行ったところ。
計算時間は10876秒。
まさかの結果で遅くなりました。NUMAよりUMAの方が計算速度が速いことがわかりました。
UMAとNUMAの使い分けですが、

によれば、
Distributedモードはメモリ帯域幅を必要とするクリエイター向けアプリケーションに適し、Localモードはゲームに適している
らしいです。つまりOpenFOAMは前者にあたるようです。シミュレーションはメモリ帯域がボトルネックになることが多いそうです。
クアッドチャンネルモード
参考

Ryzen1950Xは4枚のメモリーカードを1枚として駆動させるモードがあるようで、これがクアッドチャンネルモードいい、メモリ帯域を4倍にすることができます。
本ワークステーションはDOMINATOR PLATINUM 8GB(DDR4-3000MHz)×4枚です。データ転送速度は24.0GB/sです。
つまり、現状ではクアッドチャンネルモードでは96GB/sになっているはずです(理論上)。2枚で運用していたの時は48GB/sでした。メモリモードは同じなので、このデータ転送速度が効いているのは間違いなさそうです。
しかしながら、Ryzen1950Xの対応するメモリはDDR4-2666(4ch)らしく、CPUのデータ転送速度は、クアッドチャンネルモードで85.332GB/sです。つまり、余剰分の約11GB/sは無駄になっているようです・・・。
失敗しました。次は適切なものを選びます。勉強になりました。
以上の検討から、メモリを追加したことで並列効率が改善した理由はクアッドチャンネルモードでメモリのデータ転送速度(メモリ帯域)が大きくなったことが理由でしょう。
まとめ
- メモリを2枚⇒4枚にすると並列効率が改善した。
- メモリモードはUMAでOKでメモリ帯域が重要。
- これ以上メモリを追加しても変化しないはず。
以上